How I Scraped Nearly 2,000 Bellingham School District Staff Emails
Jamisen Renoud
May 11th, 2025 (Edited Aug 15th, 2025)
Note: This is a completely public endpoint. No login or security was bypassed.
I was snooping around the Bellingham Public School's Website and went to the contact page.
When I looked in the network tab on dev tools, I saw every time you scrolled for more results on the page, it would send a request to https://bellinghamschools.org/wp-content/themes/schoolsites/directoryHandler.php?numPosts=9&pageNumber=1, and every time increased the page number by 1.
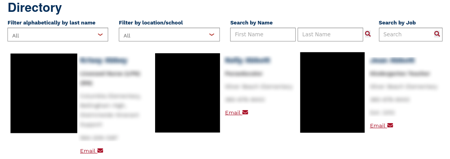
This got me thinking, upon going to https://bellinghamschools.org/wp-content/themes/schoolsites/directoryHandler.php?numPosts=9&pageNumber=1, you are greeted by a no-CSS page that just has photos and info, and it has the person's photo, name, phone number, and other info.
At the end of all that is a mailto: link with their email. So I created a simple Python script, instead of manually taking every page 1 by 1 up to 193 pages (and getting rate-limited quickly), I just used ?numPosts=9999999999&pageNumber=1 and got everything at once.
The complete source code is available here: View on GitHub
It just sends 1 request and gets all the emails! It makes a file with 1 email per line; when I ran it I got 1,732 emails.
[Yippe] Done. 1732 emails saved to emails.txt.
This post is licensed under the Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) license.